

C++11 là một phiên bản cải tiến và nâng cấp từ C++98 (hay các bạn vẫn gọi là C++), với những tính năng mới.
- Tối ưu hơn.
- Dễ sử dụng hơn.
- Dễ quản lý bộ nhớ hơn.
- Khắc phục được các nhược điểm của phiên bản C++98.
Chính vì tầm quan trọng của sự cải tiến trong C++11 mà hầu hết các dự án ngày nay đã dần sử dụng C++11 thay cho C++98. Vậy trong C++11 có những tính năng mới nào và vì sao nó lại được gọi là cải tiến và nâng cấp từ C++98, mời các bạn theo dõi 9 tính năng quan trọng của C++11 ở bên dưới.
9 tính năng quan trọng trong C++11
- Con trỏ NULL và nullptr
- Kiểu 'auto'
- Từ khóa decltype
- Giá trị mặc định khi khởi tạo và các kiểu khởi tạo
- Khai báo mới cho vòng lặp
- Từ khóa override và final
- Lambdas Expression
- Con trỏ thông minh (smart pointer)
- Move Semantics
Con trỏ NULL và nullptr
NULL được là hằng số 0 #define NULL 0.
nullptr được thêm vào C++11 để tường minh hơn khi miêu tả giá trị của việc con trỏ chưa được cấp phát.
Để hiểu rõ những bất cập đó là gì, chúng ta cùng xem một số ví dụ sau:
Ví dụ 1:
#include "stdafx.h"
#include <iostream>
using namespace std;
void f(int)
{
cout << "f(int)" << endl;
}
void f(int* i)
{
cout << "f(int*)" << endl;
}
void main()
{
f(0);
f(NULL);
}Với đoạn chương trình trên, khi ta gọi hàm f(0) thì hàm f(int) sẽ được gọi, và khi gọi hàm f(NULL) thì hàm f(int) vẫn được gọi, nhưng khi gọi f(NULL) chúng ta lại mong muốn hàm f(int*) được gọi (vì NULL tượng trưng cho con trỏ NULL), đây là một bất cập của NULL.
Chúng ta xem tiếp ví dụ 2, để thấy rằng con trỏ nullptr đã cập nhật bất cập này của NULL như thế nào.
#include "stdafx.h"
#include <iostream>
using namespace std;
void f(int)
{
cout << "f(int)" << endl;
}
void f(int* i)
{
cout << "f(int*)" << endl;
}
void main()
{
f(0);
f(nullptr);
}Với đoạn chương trình trên
- Khi ta gọi
f(0)thì hàmf(int)được gọi. - Khi ta gọi
f(nullptr)thì hàmf(int*)được gọi.
Kiểu auto
auto đã có từ phiên bản C++98. Nhưng auto trong C++11 có ý nghĩa khác với auto trong C++98. Chúng ta cùng xem 2 ví dụ sau đây:
Ví dụ 1: ý nghĩa của auto ở phiên bản C++ trước.
int i = 42; // đây là khai báo rút gọn của khai báo auto int i = 42; long long l = 42LL; // đây là khai báo rút gọn của: auto long long l = 42LL; void(*p)(int, float, char) = foo; // định nghĩa của foo: void foo(int, float, char) vector<string>::iterator it = v.begin() // v có kiểu là vector<string>
Ở ví dụ trên, chúng ta thấy rằng tất cả các biến đều phải được khai báo với kiểu một cách tường minh. Với từ khóa auto trong C++11, chúng ta sẽ viết code ngắn gọn hơn và không phải viết tường minh. Hãy xem ví dụ 2 dưới đây:
auto i = 42; // i có kiểu là int auto l = 42LL; // l có kiểu long long auto p = &foo; // p là con trỏ hàm trỏ đến hàm void foo auto it = v.begin() // v có kiểu là vector<string> auto var; // ERROR: không thể khai báo biến auto mà không có giá trị mặc định, bởi vì giá trị mặc định là nguồn dữ liệu để xác định kiểu của biến var
Với auto ở phiên bản C++11, chúng ta sẽ code một cách linh động hơn và ít phải sửa lỗi hơn khi có sự thay đổi về kiểu của một biến.
Giả sử chúng ta sửa kiểu của biến v ở đoạn code trên, thì tại dòng 4 chúng ta không phải sửa kiểu của biến it, mà biến it sẽ tự động được cập nhật kiểu theo kiểu đã thay đổi ở v.
Từ khóa decltype
Bằng cách sử dụng từ khóa decltype, trình biên dịch (compiler) sẽ tìm ra kiểu dữ liệu của một đoạn mã khai báo.
Ví dụ 1
std::map<std::string, float> coll; decltype(coll) elem;
Với đoạn mã ví dụ trên, ta khai báo biến elem có kiểu của biến coll (std::map<std::string, float>).
Ví dụ 2:
template <typename T1, typename T2>
auto add(T1 t1, T2 t2) -> decltype(t1 + t2)
{
return t1 + t2;
}Với đoạn mã ví dụ trên, kiểu trả về của hàm add sẽ là kiểu trả về của kết quả t1 + t2, cụ thể:
t1làint,t2làintthì kiểu trả về của hàmaddlàintt1làint,t2làfloatthì kiểu trả về của hàmaddlàfloatt1làfloat,t2làdoublelà thì kiểu trả về của hàmaddlàdouble- ...
Giá trị mặc định khi khởi tạo và các kiểu khởi tạo
Khi khai báo một biến thì biến sẽ có giá trị khởi tạo được xác định hoặc không xác định tùy thuộc vào cách khai báo. Đối với C++11 chúng ta có thể sử dụng hai dấu nháy nhọn để khởi tạo biến an toàn tránh mất dữ liệu ngoài ý muốn.
Để hiểu rõ thêm, chúng ta cùng xem ví dụ bên dưới:
//Ví dụ 1
int a1[] = { 1, 2, 3.5 }; // OK, nhưng giá trị của a1[2] là 3 (thay vì 3.5) --> mất dữ liệu
int a2[] { 1, 2, 3.5 }; // Error, không thể khai báo số thực ở mảng số nguyên
int a3[] { 1, 2, 3 }; // OK
//Ví dụ 2:
int i; // i có giá trị mặc định là một số không xác định (số rác)
int j{}; // j có giá trị mặc định là 0
//Ví dụ 3
int x1(5.3); // OK, nhưng giá trị của x1 là 5 (mất dữ liệu), đây là cách khởi tạo thông thường của c++ phiên bản cũ
int x2 = 5.3; // OK, nhưng giá trị của x1 là 5 (mất dữ liệu), đây là cách khởi tạo thông thường của c++ phiên bản cũ
int x3{5.0}; // ERROR: không thể ép kiểu float qua int với cách khởi tạo ở C++11
int x4 = {5.3}; // ERROR: không thể ép kiểu float qua int với cách khởi tạo ở C++11
char c1{7}; // OK: mặc dù 7 là số int, nhưng 7 không bị mất dữ liệu (narrowing)
char c2{99999}; // ERROR: vì 99999 nằm ngoài miền giá trị của kiểu char
std::vector<int> v1 { 1, 2, 4, 5}; // OK
std::vector<int> v2 { 1, 2.3, 4, 5.6 }; // ERROR: vì 5.6 là kiểu double không phải kiểu int
Khai báo mới cho vòng lặp
C++11 ra mắt một dạng mới của vòng lặp for nhằm thu gọn vòng lặp và dễ dàng sử dụng hơn. Dạng này cũng tương tự như vòng lặp foreach ở các ngôn ngữ lập trình cấp cao như Java, C#,...
Cú pháp của dạng vòng lặp for này như sau:
for (decl : coll) {
Statement
}Hãy xem những ví dụ dưới đây để hiểu hơn về vòng lặp for mới này:
// Ví dụ 1
for (int i : {2, 3, 5, 7, 9, 13, 17, 19 }) {
std::cout << i << std::endl;
}
// Ví dụ 2
std::vector<double> vec;
for (auto& elem : vec){
elem *= 3;
}
Trong cách duyệt mảng của thư viện std (std:vector, std:list,...) cũng được rút gọn, đơn giản và dễ hiểu hơn:
// Cách 1: sử dụng phương thức begin/end bên trong của mảng:
for (auto _pos = coll.begin(), _end = coll.end(); _pos != _end; ++_pos) {
decl = *_pos;
statement
}
// Cách 2: KHÔNG sử dụng phương thức begin/end bên trong của mảng:
for (auto _pos = begin(coll), _end = end(coll); _pos != _end; ++_pos) {
decl = *_pos;
statement
}Từ khóa 'override' và 'final'
Từ khóa override
Cũng tương tự như phần ở trên, từ khóa override và final được thêm vào trong C++11 để khắc phục những bất cập trong lập trình hướng đối tượng (OOP).
Hãy cùng tham khảo 2 trường hợp bất cập trong C++ phiên bản cũ:
// Trường hợp 1
class B
{
public:
virtual void f(short)
{
std::cout << "B::f" << std::endl;
}
};
class D : public B
{
public:
virtual void f(int)
{
std::cout << "D::f" << std::endl;
}
};
// Trường hợp 2:
class B
{
public:
virtual void f(int) const
{
std::cout << "B::f" << std::endl;
}
};
class D : public B
{
public:
virtual void f(int)
{
std::cout << "D::f" << std::endl;
}
};
Mục đích của đoạn code trên là: viết class D kế thừa từ class B và viết lại hàm f (override f) ở class D, nhưng gặp một số nhược điểm sau:
- Trường hợp 1: f ở B có tham số kiểu truyền vào là kiểu short, còn hàm f ở D có tham số truyền vào là kiểu int, vì vậy f ở class B không được viết lại ở class D (hay nói cách khác D::f và B::f là hai hàm tách biệt, không có liên quan đến nhau)
- Trường hợp 2: chúng ta thấy f ở B và f ở D đều có cùng tham số truyền vào là int, nhưng f ở B là một hàm hằng (const function), còn f ở D không phải là hàm hằng, vì vậy f ở class B không được viết lại ở class D mặc dù 2 hàm f đều có chùng tham số
Chính vì những nhược điểm đó mà từ khóa override đã ra đời để giải quyết vấn đề trên. Từ khóa override ở sau một hàm là để chỉ ra rằng hàm này được viết lại từ hàm của lớp cha, nếu ở lớp cha không tồn tại hàm này thì trình biên dịch sẽ báo lỗi.
Vì dụ về cách sử dụng từ khóa override:
class B
{
public:
virtual void f(short)
{
std::cout << "B::f" << std::endl;
}
};
class D : public B
{
public:
virtual void f(short) override
{
std::cout << "D::f" << std::endl;
}
};
Một lợi thế rất quan trọng nữa khi sử dụng từ khóa override là: xét ví dụ ở trên, nếu bạn hoặc một đồng nghiệp khác của bạn vô tình hoặc cố ý sửa tên hàm hoặc tham số đầu vào của hàm f ở class B thì lúc biên dịch sẽ bị lỗi, điều này chỉ ra cho chúng ta thấy nếu muốn sửa một phương thức có tên là f ở lớp cha mà lớp con đã viết lại bằng từ khóa override thì phải sửa luôn cả phương thức f ở lớp con.
Từ khóa final
Từ khóa final ở sau một hàm muốn chỉ ra rằng tất cả class con kế thừa từ class này KHÔNG được phép viết lại hàm này. Nếu chúng ta cố tình viết lại hàm có từ khóa final thì lúc biên dịch sẽ bị lỗi.
Ví dụ về cách sử dụng từ khóa final:
class B
{
public:
virtual void f(int) final
{
std::cout << "B::f" << std::endl;
}
};
class D : public B
{
public:
virtual void f(int)
{
std::cout << "D::f" << std::endl;
}
};Với ví dụ trên, chúng ta thấy rằng hàm f ở class B đã có từ khóa final, nhưng class D vẫn cố tình viết lại hàm f, lúc này khi biên dịch sẽ bị lỗi.
Lambda expression
Những hàm vô danh được gọi là lambda (còn được gọi là những hàm không có tên).
Một cách cơ bản lambda expession có cú pháp như sau:
[capture] (parameters) -> returnType { // TODO: }- Phạm vi sử dụng biến
[=]: cho phép sử dụng tất cả biến trong cùng phạm vi thông qua cách truyền tham số (pass by value)[&]: cho phép sử dụng tất cả biến trong cùng phạm vi thông qua cách truyền tham chiếu (pass by reference)[this]: cho phép sử dụng tất cả biến trong cùng phạm vi class- Bạn cũng có thể cho phép chỉ ra những biến cụ thể được phép sử dụng bằng cách:
[a, &b] (parameters) -> returnType { // TODO: }- Biến
ađược truyền vào theo dạng tham số - Biến
bđược truyền vào theo dạng tham trị
- Biến
- Bạn cũng có thể không cho phép sử dụng bất kì biến bên ngoài bằng cách:
[] (parameters) -> returnType { // TODO: }
Chúng ta cùng theo dõi một vài ví dụ dưới đây để hiểu thêm về cách sử dụng lambdra expression.
// Ví dụ 1:
[] {
std::cout << "hello lambda" << std::endl;
} (); // xuất ra "hello lambda"
// Ví dụ 2:
auto l = [] {
std::cout << "hello lambda" << std::endl;
};
l(); // xuất ra "hello lambda"
// Ví dụ 3:
auto l = [](const std::string& s) {
std::cout << s << std::endl;
};
l("hello lambda"); // xuất ra "hello lambda"
// Ví dụ 4: chỉ cho phép sử dụng 2 biến x và y (x: truyền tham số, y: truyền tham trị)
int x = 0;
int y = 42;
auto qqq = [x, &y] {
std::cout << "x: " << x << std::endl;
std::cout << "y: " << y << std::endl;
++y;
};
// Ví dụ 5: không sử dụng biến bên ngoài, không có tham số, kiểu trả về là double
[]() -> double {
return 42.0;
}
Con trỏ thông minh (Smart pointers)
Được hỗ trợ bởi thư viện <memory>
Bao gồm 3 loại con trỏ:
shared_ptrweak_ptrunique_ptr
Con trỏ thông minh ra đời để giải quyết một số nhược điểm trong việc quản lý bộ nhớ ở phiên bản C++ trước.
shared_ptr
shared_ptr được sử dụng khi một vùng nhớ được chia sẻ cho nhiều con trỏ.
Ví dụ:
std:: shared_ptr<int> p1(new int(42)); std:: shared_ptr<int> p2 = p1; *p1 = 30; cout << "p1: " << *p1 << endl; cout << "p2: " << *p2 << endl;
Với ví dụ trên, ta thấy con trỏ p1 và p2 được lưu trữ ở bộ nhớ stack nhưng p1 và p2 cùng trỏ tới 1 vùng nhớ.
Như chúng ta đã biết, một biến được lưu ở vùng nhớ stack sẽ tự động được hủy khi chương trình chạy ra khỏi phạm vi (scope) chứa biến đó.
Điều đặc biệt ở đây là vùng nhớ dùng chung của con trỏ p1 và con trỏ p2 sẽ bị hủy khi biến p1 và p2 bị hủy (vùng nhớ dùng chung của p1 và p2 sẽ bị hủy khi không còn con trỏ trỏ tới nó).
Đây chính là lợi ích của shared_ptr mang lại.
Ngoài ra chúng ta cũng có thể tự định nghĩa một phương thức hủy cho shared_ptr. Ví dụ ta sẽ xuất ra thông báo "Deleted p" trước khi hủy con trỏ p.
shared_ptr<string> pNico(new string("nico"), [](string* p) {
cout << "Deleted p" << endl;
});Xử lý mảng và shared_ptr
- Chú ý rằng: mặc định khi hủy vùng nhớ
shared_ptrsẽ gọidelete(không phảidelete[]) - Vì vậy, nếu bạn sử dụng
new[]để tạo một mảng đối tượng, bạn phải định nghĩa một cách thức hủy cho riêng bạn. Bạn có thể làm điều này bằng cách định nghĩa một phương thức hủy hoặc một con trỏ hàm hoặc lamdba gọidelete[]để hủy một con trỏ mảng như bình thường.
Ví dụ: định nghĩa một cách thức hủy bằng lamdba:
shared_ptr<MyClass> p(new MyClass[10], [](MyClass* p) {
delete[] p;
});
Chúng ta cũng có thể sử dụng công cụ hỗ trợ chính thức default_delete cho con trỏ unique_ptr (sẽ được giới thiệu ở bên dưới) để gọi delete[] giống như delete.
shared_ptr<MyClass> p(new MyClass[10], default_delete<MyClass[]>());
shared_ptr không có delete[] mặc định như unique_ptr.
std::unique_ptr<int[]> p(new int[10]); // OK std::shared_ptr<int[]> p(new int[10]); // ERROR: compile lỗi
unique_ptr
unique_ptr được sử dụng vùng nhớ được khởi tạo ra và không chia sẻ cho bất kì con trỏ nào khác (có nghĩa là nó không có hàm khởi tạo sao chép - copy constructor) nhưng nó có thể chuyển vùng nhớ cho một con trỏ unique_ptr khác (gọi là khởi tạo di chuyển - move constructor).
Vậy lợi ích của con trỏ unique_ptr là gì, hãy xét ví dụ dưới đây xem có vấn đề gì không nhé:
// Giả sử chúng ta đã có ClassA hoàn chỉnh
void f()
{
ClassA* ptr = new ClassA; //khởi tạo một đối tượng một cách tường minh
// thực thi một vài tương tác lên con trỏ ptr
//....
delete ptr; // hủy vùng nhớ mà con trỏ ptr đang trỏ tới.
}Với ví dụ trên, chúng ta thấy rằng việc hủy con trỏ ptr ở dòng thứ 7 tiềm ẩn rủi ro gây ra lỗi chương trình, trong trường hợp trước khi hủy con trỏ ptr chúng ta đã cho một con trỏ khác ptr2 cùng trỏ tới vùng nhớ mà ptr đang trỏ, và chúng ta đã hủy vùng nhớ này thông qua con trỏ ptr2. Vì vậy khi hủy vùng nhớ dùng chung thông qua con trỏ ptr sẽ gây ra lỗi ngừng chương trình đột ngột. Ví dụ:
void f()
{
ClassA* ptr = new ClassA; //khởi tạo một đối tượng một cách tường minh
ClassA* ptr2 = ptr; // cho con trỏ ptr2 cùng trỏ tới vùng nhớ mà ptr đang trỏ
delete ptr2; // xóa vùng nhớ dùng chung thông qua con trỏ ptr2
delete ptr; // hủy vùng nhớ mà con trỏ ptr đang trỏ tới
}Trong trường hợp này giải quyết như thế nào?
Giải pháp 1: sử dụng try ... catch
void f()
{
ClassA* ptr = new ClassA; //khởi tạo một đối tượng một cách tường minh
try {
// thực thi một vài tương tác lên con trỏ ptr
//....
delete ptr; // hủy vùng nhớ mà con trỏ ptr đang trỏ tới
}
catch (...) // ... có ý nghĩa cho bất cứ ngoại lệ nào
{
throw;
}
}Giải pháp 2:
void f()
{
std::unique_ptr<ClassA*> ptr (new ClassA); //khởi tạo một đối tượng một cách tường minh sử dụng unique_ptr
// thực thi một vài tương tác lên con trỏ ptr
//....
}
// con tỏ ptr sẽ tự động được hủy khi hàm ptr ra khỏi phạm vi của nó (hàm f kết thúc)Một số ví dụ về cách sử dụng và khởi tạo con trỏ unique_ptr:
std::unique_ptr<int> up = new int; // Lỗi, không thể khởi tạo con trỏ unique_ptr như một cách thông thường
std::unique_ptr<int> up(new int); // OK
int* sp = up.release(); // sp sẽ trỏ tới vùng nhớ up đang trỏ tới, đồng thời up sẽ không trỏ tới nullptr
string* sp = new string("hello");
unique_ptr<string> up1(sp); // OK
unique_ptr<string> up2(sp); // ERROR: up1 và up2 không thể cùng trỏ tới cùng một vùng nhớ (không thể chia sẻ tài nguyên với nhau)
unique_ptr<string> up3(std::move(up1)); //OK, chuyển vùng nhớ của up1 qua up3, và up1 sẽ trỏ tới nullptr
unique_ptr<string> up4;
up4 = up1; //ERROR: không thể cho 2 con trỏ unique_ptr cùng trỏ tới 1 vùng nhớ.
unique_ptr<ClassA> ptr; //create a unique_ptr
ptr = new ClassA; // ERROR
ptr = unique_ptr<ClassA>(new ClassA); // OK, hủy đối tượng cũ và khởi tạo đối tượng mới
up = nullptr; // hủy đối tượng (hoặc bạn có thể gọi up.reset())Xử lý unique_ptr với mảng
std::unique_ptr<std::string> up(new std::string[10]); sẽ bị lỗi lúc chạy (run time error).
Mặc định unique_ptr sẽ gọi delete để hủy vùng nhớ nó đang trỏ tới. Vì vậy: std::unique_ptr<std::string[]> up(new std::string[10]);
Tương tự như shared_ptr bạn có thể tự tạo riêng cho unique_ptr cách thức hủy khi khởi tạo đối tượng như sau:
// Giả sử rằng chúng ta đã có sẵn ClassA
// Cách 1: khởi tạo con trỏ với 1 đối tượng
class ClassADeleter
{
public:
void operator () (ClassA* p) {
std::cout << "call delete for ClassA object" << std::endl;
delete p;
}
};
void main(int argc, _TCHAR* argv[])
{
std::unique_ptr<ClassA, ClassADeleter> up(new ClassA());
}
// Cách 2: sử dụng lamdba để hủy con trỏ khởi tạo với mảng
auto l = [] (ClassA* p) {
// Thao tác bất kì trước khi hủy con trỏ p
delete[] p;
};
std::unique_ptr<ClassA, decltype(l)>> up (new ClassA[10], l);weak_ptr
Con trỏ shared_ptr sẽ có một vài bất cập nếu chúng ta lạm dụng nó, ví dụ:
class Person
{
public:
string name;
shared_ptr<Person> mother;
shared_ptr<Person> father;
vector<shared_ptr<Person>> kids;
Person(const string& n, shared_ptr<Person> m = nullptr, shared_ptr<Person> f = nullptr)
: name(n), mother(m), father(f)
{
}
~Person()
{
cout << "delete " << endl;
}
};
shared_ptr<Person> initFamily<const string& name)
{
shared_ptr<Person> mom(new Person(name + "'s mon"));
shared_ptr<Person> dad(new Person(name + "'s dad"));
shared_ptr<Person> kid(new Person(name, mom, dad));
mom->kids.push_back(kid);
dad->kids.push_back(kid);
return kid;
}
void main()
{
shared_ptr<Person> p = initFamily("Nico");
}Dưới đây là hình ảnh minh họa cho đoạn code trên:
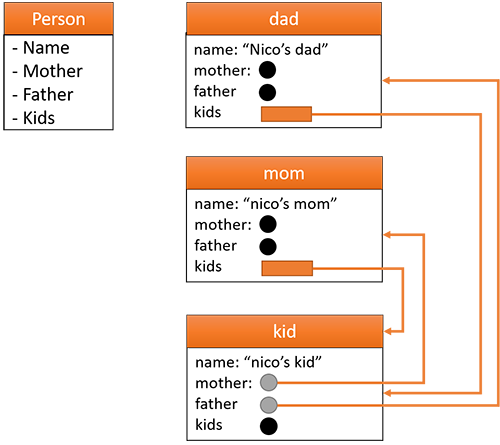
Với ví dụ trên chúng ta thấy dad->kids, mom->kids trỏ tới kid và ngược lại kid->father trỏ tới dad và kid->mother trỏ tới mom, chúng ta gọi kiểu trỏ này là sự phụ thuộc vòng tròn (hay gọi là trỏ lặp - dependency cycles). Trong trường hợp này shared_ptr không giải quyết được, chính vì thế weak_ptr đã ra đời.
Con trỏ weak_ptr là con trỏ sẽ trỏ đến một đối tượng shared_ptr, nhưng số lượng tham chiếu đến vùng nhớ được quản lý bởi shared_ptr không tăng lên. weak_ptr được sử dụng để khử những con trỏ lặp như ví dụ trên, cụ thể như sau:
class Person
{
public:
string name;
shared_ptr<Person> mother;
shared_ptr<Person> father;
vector<weak_ptr<Person>> kids; // sử dụng weak_ptr để khử con trỏ lặp
Person(const string& n, shared_ptr<Person> m = nullptr, shared_ptr<Person> f = nullptr)
: name(n), mother(m), father(f)
{
}
~Person()
{
cout << "delete " << endl;
}
};
shared_ptr<Person> initFamily<const string& name)
{
shared_ptr<Person> mom(new Person(name + "'s mon"));
shared_ptr<Person> dad(new Person(name + "'s dad"));
shared_ptr<Person> kid(new Person(name, mom, dad));
mom->kids.push_back(kid);
dad->kids.push_back(kid);
return kid;
}
void main()
{
shared_ptr<Person> p = initFamily("Nico");
}Move semantics
Move semantics hay còn gọi là move constructor, là tính năng mới vô cùng quan trọng, nó giúp cho tối ưu về tốc độ trong hướng đối tượng. Đây là một tính năng lớn và có rất nhiều điều cần thảo luận, dưới đây tôi chỉ đưa ra cho các bạn về khái niệm và một phần gợi mở để các bạn thấy được vì sao move semantics lại tối ưu được tốc độ.
Chúng ta hãy khảo sát ví dụ sau: giả sử rằng X là một class có một biến con trỏ đang trỏ tới một vùng nhớ, và biến ngày có tên là m_pResource. Theo cách thông thường thì khi chúng ta sẽ viết toán tử = cho class này như sau:
class X
{
public:
X()
{
cout << "Default contructor" << endl;
}
X(const X& lvalue) // copy constructor
{
cout << "Copy contructor" << endl;
// [...]
// Hủy tài nguyên (vùng nhớ) m_pResource đang trỏ tới
// Tạo một vùng nhớ mới có giá trị như rhs.m_pResource đang trỏ tới
// Gán vùng nhớ vừa tạo cho con trỏ m_pResource
// [...]
}
//[...]
};
X foo()
{
X x;
//[...]
return x;
}
void main()
{
X x1 = foo();
}Giải thích hàm foo()
- Hàm
foo()tạo ra một đối tượngxthuộcclass X, sau đó sẽ xử lý đối tượng này theo một mục đích nhất định[...], tiếp theo hàmfootrả về đối tượngx - Trong hàm
main, chúng ta khai báo một biênx1thuộcclass Xvà được gán bằng kết quả trả về của hàmfoo
x1 không được gán trực tiếp bởi biến x trong hàm foo mà được gán bởi một đối tượng được sao chép ra từ x, sau đó x sẽ bị hủy khi hàm foo kết thúc.
Việc tạo ra một đối tượng sao chép từ x, rồi gán cho x1, sau đó hủy x là rất tốn chi phí, để gán trực tiếp từ x trong hàm foo qua x1 sử dụng move semantics (hay còn gọi là move constructor), cụ thể như sau:
class X
{
public:
// default contructor
X()
{
cout << "Default contructor" << endl;
}
// copy constructor
X(const X& lvalue)
{
cout << "Copy contructor" << endl;
// [...]
// Hủy tài nguyên (vùng nhớ) m_pResource đang trỏ tới
// Tạo một vùng nhớ mới có giá trị như rhs.m_pResource đang trỏ tới
// Gán vùng nhớ vừa tạo cho con trỏ m_pResource
// [...]
}
// move constructor
X(X&& rvalue)
{
cout << "Move constructor" << endl;
// [...]
// Hoán đổi vùng nhớ của this->m_pResource và rhs.m_pResource
// [...]
}
};
X foo()
{
X x;
//[...]
return x;
}
void main()
{
X x1 = foo();
}