

Danh sách liên kết là 1 cấu trúc dữ liệu cơ bản, được sử dụng để khắc phục hạn chế của mảng (cố định về kích thước). C++ nói chung và cụ thể là thư viện STL đã cung cấp sẵn một kiểu dữ liệu List. Tuy nhiên tôi vẫn muốn chia sẻ bài viết này để nêu rõ về bản chất của danh sách liên kết và một số thao tác cơ bản trên nó.
Tổ chức danh sách liên kết đơn
Cũng giống như mảng, danh sách liên kết bao gồm các phần tử, có mối liên hệ với nhau, mỗi phần tử đó là một Node, mỗi Node sẽ lưu trữ 2 thông tin:
- Thông tin dữ liệu: Lưu trữ các thông tin dữ liệu cần thiết (giá trị số, chuỗi, đối tượng...).
- Thông tin liên kết: Lưu trữ địa chỉ của phần tử kế tiếp trong danh sách, hoặc lưu trữ giá trị NULL (nullptr) nếu phần tử đó nằm cuối danh sách.
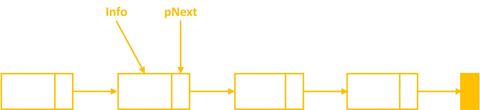
Một cách tổng quát ta có:
struct Node
{
Data info;
Node* next;
};info: với Data có thể là bất kỳ kiểu dữ liệu nào: int, short, char*, object (Person, Duck...).next: lưu thông tin vị trí của Node kế tiếp đang ở đâu trên bộ nhớ (địa chỉ của Node kết tiếp).
Mỗi phần tử trong trong danh sách liên kết đơn là một biến được cấp phát động, danh sách liên kết đơn chính là sự liên kết các biến này với nhau do đó ta hoàn toàn chủ động về số lượng các phần tử.
Giả sử Data là int, Node của danh sách liên kết sẽ được định nghĩa như sau:
struct Node
{
int value;
Node* next;
};Một số thao tác cơ bản trên danh sách liên kết đơn
Trong danh sách liên kết đơn, các Node sẽ không được lưu liên tiếp nhau trên bộ nhớ, Node trước sẽ mang thông tin địa chỉ của Node sau, như vậy nếu bạn xử lý lỗi một Node sẽ dẫn đến tình huống xấu là mất thông tin truy cập các Node phía sau.
Code cơ bản khi hình thành 1 danh sách liên kết như bên dưới:
struct Node
{
int data;
Node* next;
Node (int _data)
{
data = _data;
next = nullptr;
}
};
struct List
{
Node* head;
Node* tail;
List() {
head = nullptr;
tail = nullptr;
}
};Nếu biết được địa chỉ đầu tiên trong danh sách liên kết ta có thể dựa vào thông tin next để truy xuất đến các phần tử còn lại, do đó ta sẽ dùng một con trỏ head để lưu lại địa chỉ Node đầu tiên của danh sách.
tail là 1 trường hợp tối ưu việc truy cập nhanh nhất vào cuối danh sách, do đó bạn không cần thiết phải có tail khi không có nhu cầu, nếu có tail thì bạn phải lưu ý cập nhật lại tail mỗi lần thêm hoặc xóa phần tử ở cuối danh sách.
Chèn vào đầu danh sách
Như đã trình bày ở trên, khi thao tác với mỗi Node trên danh sách liên kết cần thực hiện cẩn thận, đúng thứ tự để tránh mất thông tin của các Node phía sau.
- Bước 1: gán next của Node mới trỏ đến Node đầu (cũ):
node->next = head; - Bước 2: cập nhập lại giá trị head:
head = node;
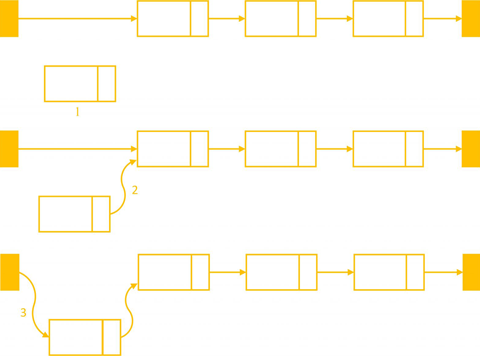
insertToHead(Node* node)
{
node->next = head;
head = node;
}Chèn vào cuối danh sách
Chèn vào cuối danh sách chúng ta chỉ cần cập nhập lại con trỏ tail.
- Bước 1: gán lại
nextcủa Node cuối cùng (cũ) sẽ trỏ đến Node mới:tail->next = node;- Sẽ có 1 trường hợp ngoại lệ là danh sách chưa có Node nào, thì phải xử lý riêng đó là khởi tạo danh sách.
- Bước 2: cập nhập lại giá trị
tail, bây giờ Node cuối của danh sách là Node vừa thêm:tail = node;
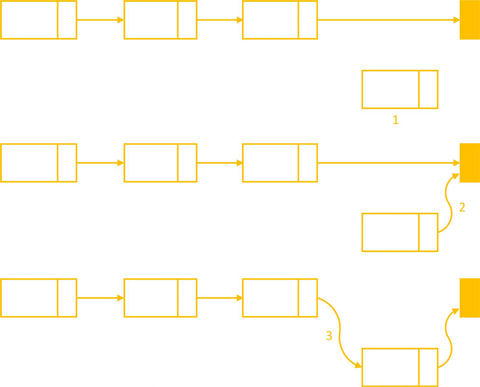
insertToTail(Node* node)
{
if (tail != nullptr)
tail->next = node;
else
{
head = node;
tail = node;
}
}Chèn vào danh sách sau một Node q trong danh sách
Chèn vào danh sách sau một phần tử q nào đó, chèn vào giữa danh sách không cần cập nhập lại hai con trỏ pHead và pTail tuy nhiên chúng ta cần hết sức cần thận để tránh mất dữ liệu phía sau.
- Bước 1: gán
nextcủa Node mới bằng địa chỉ của Node sauq:node->next = q->next;- Trường hợp ngoại lệ là
qchính làtail, do đó ta quay lại bài toán chèn vào cuối danh sách.
- Trường hợp ngoại lệ là
- Bước 2: cập nhập lại
q->nexttrỏ đến Node mới:q->next = node;
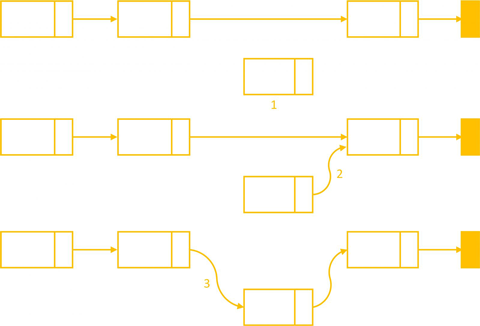
insertAfter(Node* node, Node* q)
{
if (q != tail)
{
node->next = q->next;
q->next = node;
}
else
{
insertToTail(node);
}
}Xóa một phần tử đầu danh sách
Xóa 1 phần tử ở đầu danh sách không chỉ đơn giản là cập nhập lại biến con trỏ head, mà ta phải giải phóng được vùng nhớ của Node cần xóa.
- Bước 1: Khai báo một con trỏ p để lưu lại địa chỉ của Node đầu tiên:
Node* temp = head;- Trường hợp ngoại lệ cần xử lý là nếu danh sách không có phần tử nào thì phải thoát trước khi thực hiện xóa.
- Bước 2: cập nhập lại giá trị của head:
head = head->next; - Bước 3: giải phóng vùng nhớ của Node cần xóa:
delete temp;
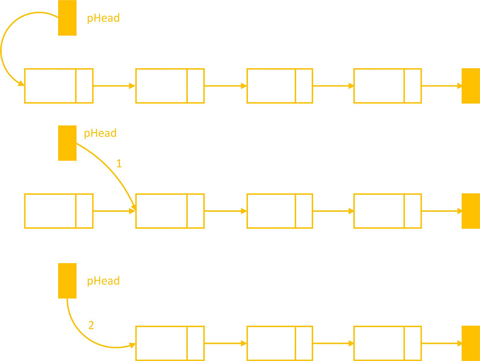
removeAtHead()
{
if (head == nullptr)
return;
Node* temp = head;
head = head->next;
delete temp;
}Xóa một Node đứng sau Node q
Để xóa một phần tử đứng sau phần tử q, ta thực hiện các bước sau:
- Bước 1: Khai báo một con trỏ p để lưu lại địa chỉ của Node đầu tiên: Node* temp = q->next;
- Bước 2: cập nhập lại giá trị next của Node q: q->next = temp->next;
- Bước 3: giải phóng vùng nhớ của Node cần xóa: delete temp;
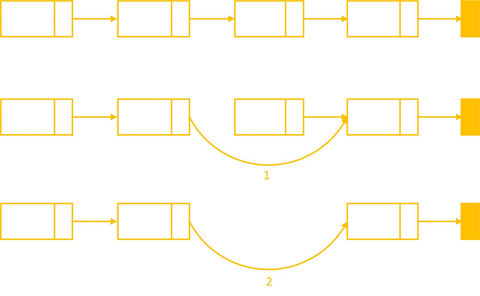
removeAfter(Node* q)
{
Node* temp = q->next;
q->next = temp->next;
delete temp;
}Duyệt danh sách
Khi có được giá trị của head ta có thể dựa và thông tin next để duyệt lần lượt các phần tử của danh sách.
Node* p;
p = list.head;
while (p != NULL)
{
// Process Node
p = p->next;
}Lời kết
Source code được viết theo hướng cấu trúc để các bạn chưa có khái niệm về hướng đối tượng có thể tiếp cận một cách dễ dàng. Có thể thấy được, danh sách liên kết đã khắc phục được nhược điểm của mảng - đó là kích thước cố định.
#include
using namespace std;
struct Node
{
int data;
Node* next;
Node (int _data)
{
data = _data;
next = nullptr;
}
};
struct List
{
Node* head;
Node* tail;
List() {
head = nullptr;
tail = nullptr;
}
insertToHead(Node* node)
{
node->next = head;
head = node;
}
insertToTail(Node* node)
{
if (tail != nullptr)
tail->next = node;
else
{
head = node;
tail = node;
}
}
insertAfter(Node* node, Node* q)
{
if (q != tail)
{
node->next = q->next;
q->next = node;
}
else
{
insertToTail(node);
}
}
removeAtHead()
{
if (head == nullptr)
return;
Node* temp = head;
head = head->next;
delete temp;
}
removeAfter(Node* q)
{
Node* temp = q->next;
q->next = temp->next;
delete temp;
}
iterate()
{
Node* p;
p = head;
while (p != NULL)
{
// TODO:
cout << p->value << endl;
p = p->next;
}
}
Node* find(int _value)
{
Node* p;
p = head;
while (p != NULL)
{
if (p->value == _value)
return p;
p = p->next;
}
return nullptr;
}
};
// Test
int main()
{
List li;
li.insertToHead(3);
li.insertToHead(2);
li.insertToTail(4);
Node* q = li.find(3);
li.insertAfter(new Node(9), q);
return 0;
}